On April 16, 2026, Anthropic shipped Claude Opus 4.7 — the next iteration of its flagship model, laser-focused on long-context tasks, autonomous reasoning, and disciplined execution across multi-hour engineering projects. The launch arrives just as the entire industry is shifting weight from single-shot prompts to agentic workflows — sessions where a model plans, writes code, fixes bugs, and reports progress for hours or days without human supervision. Opus 4.7 is tuned exactly for that: slower error cascades, better cross-session memory, and visibly stronger results on engineering benchmarks.
What’s New in Claude Opus 4.7
The new model keeps the same pricing as its predecessor ($5 per million input tokens, $25 per million output tokens), but ships meaningful upgrades across architecture and reasoning control. This is not a cosmetic bump — Anthropic explicitly notes the model is “substantially better at following instructions” and warns that some teams will need to re-tune their prompts to get the full benefit.
Key changes versus Opus 4.6:
xhigheffort level — a new reasoning tier sitting betweenhighandmax, giving finer control over the cost-to-quality trade-off.- Task budgets — a parameter that caps token spend inside long agentic runs without manual interruption.
- Upgraded vision — images up to 2,576 px on the long edge (~3.75 megapixels), more than 3× the previous capacity.
/ultrareviewcommand — a dedicated code-review mode for Claude Pro and Max subscribers.- Auto mode — autonomous decision-making expanded to Max plan users.
- Updated tokenizer — better text handling, but the same prompt can now generate 1.0–1.35× more tokens than before, which matters for API budgets.
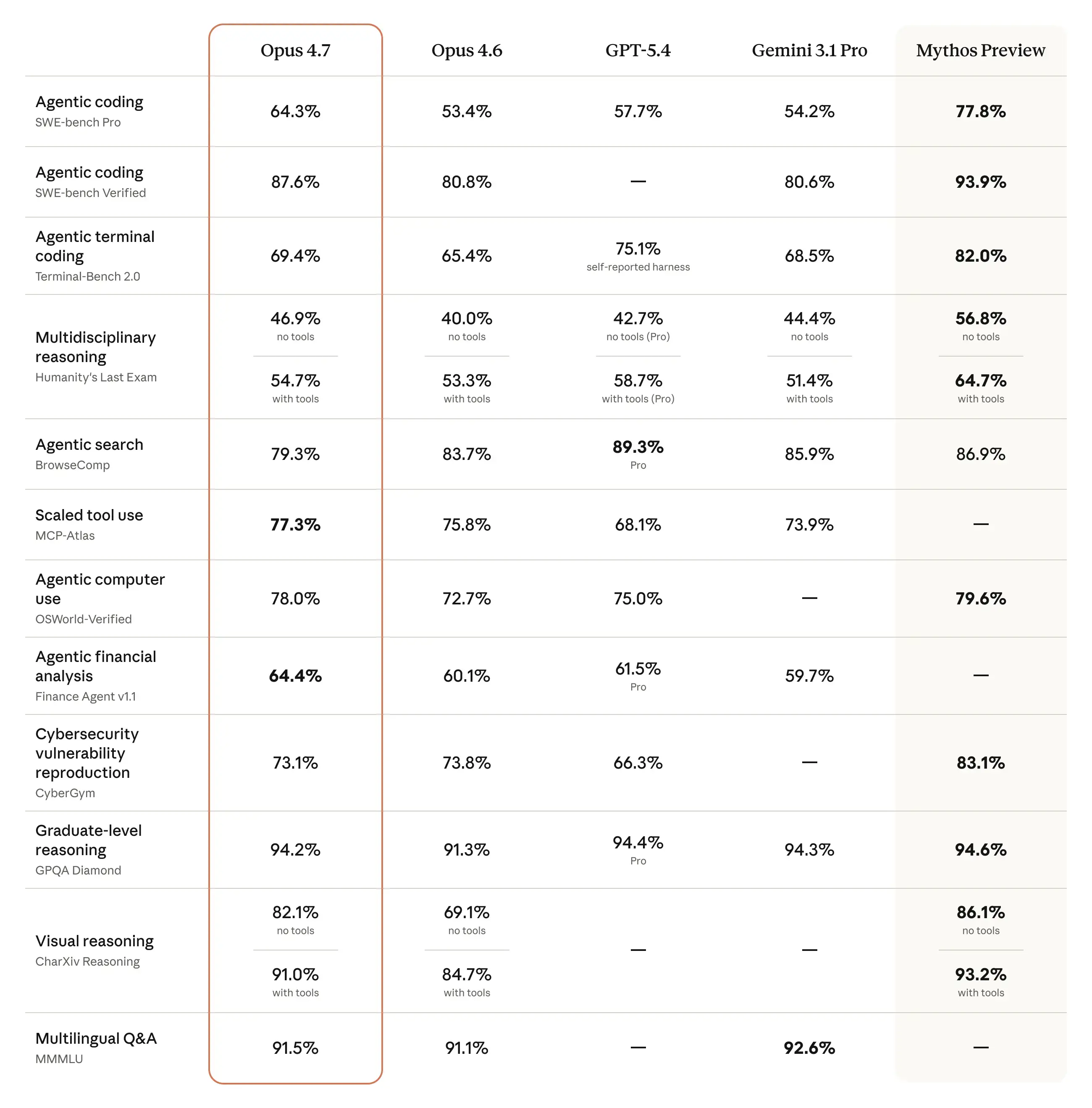
Benchmarks: Real Production Numbers, Not Marketing
Anthropic backs the release with hard numbers measured alongside production partners. That’s a tonal shift — instead of closed academic evaluations, the company is leaning on data from real engineering environments.
| Benchmark / Partner | Opus 4.7 | Opus 4.6 |
|---|---|---|
| Replit (93-task coding test) | +13% | baseline |
| Rakuten (production tasks) | 3× more resolutions | baseline |
| CursorBench | 70% success | 58% success |
| GDPval-AA (finance/legal) | state-of-the-art | lower |
| XBOW (pentesting) | 98.5% visual acuity | — |
The Rakuten result deserves attention — a 3× jump in resolved production tasks isn’t just about code quality. It signals the model is dramatically more resistant to “getting stuck” in long workflows. That translates directly to operating cost: fewer iterations, fewer wasted tokens, fewer human corrections needed downstream.
Agentic Behavior and Cross-Session Memory
The most important direction in Opus 4.7 is operating across long time horizons. The model has been tuned for scenarios where an agent runs for hours or days — writing code, running tests, resuming tasks after interruption, and keeping decisions consistent along the way.
The key improvements in this area:
- Better cross-session memory use — the model handles earlier notes, logs, and project artifacts more effectively.
- Tool coordination — smoother chaining of function calls inside multi-step plans.
- Long-context stability — fewer “fatigue hallucinations” when working with large repositories.
For teams building their own integrations with Claude-class models — whether through the API or Claude Code — this means you can push more logic into the model itself and strip out some of the orchestration layers that used to be required to keep things on the rails.
Tokenizer Changes: What This Means for Your API Bill
The updated tokenizer improves text handling, but it comes with a practical consequence: the same prompts can cost more. Anthropic reports a 1.0–1.35× multiplier depending on content, and at xhigh and max effort the model also produces more output tokens — deliberately, in service of higher reliability.
What this means in practice for production teams:
- Revisit monthly budgets — especially if you run large contexts or many parallel agents.
- Audit your long prompts — non-Latin scripts and code with many special characters are particularly sensitive.
- Run A/B cost tests — even at identical per-million rates, the effective cost per request can rise 10–35%.
Safety and Prompt Injection Resistance
The external safety assessment is cautiously positive. Opus 4.7 is judged as “largely well-aligned and trustworthy,” with visible gains in honesty and resistance to prompt injection — one of the biggest attack vectors against agentic systems.
The downside is a modest regression in harm-reduction advice, which Anthropic openly flags in the documentation. For teams building products in regulated spaces — health, finance, legal — that means maintaining additional filter layers and validation, just as with earlier models in this class.
Availability and Integrations
Claude Opus 4.7 is available from day one across every major platform:
- Claude.ai — Free, Pro, Max, and Teams/Enterprise users.
- Anthropic API — under the model ID
claude-opus-4-7. - Amazon Bedrock — in all regions supporting the Claude family.
- Google Cloud Vertex AI — full integration with GCP pipelines.
- Microsoft Foundry — a new distribution channel in the Microsoft ecosystem.
Pro and Max subscribers also get access to the /ultrareview command, which kicks off a dedicated code-review session where the model spends a larger compute budget on verifying changes, catching regressions, and proposing justified refactors.
Summary
Claude Opus 4.7 is an evolutionary model — but in the places that actually matter for production teams: long agentic sessions, precise instruction-following, discipline across multi-hour engineering projects, and finer control over the cost-to-quality trade-off thanks to the new xhigh tier. The 3× lift in resolved production tasks at partners like Rakuten shows the improvement goes beyond benchmarks and translates into real operational savings.
For companies building workflows on top of AI-powered SEO or their own agentic tooling, Opus 4.7 sends a clear signal: the model layer is absorbing another chunk of autonomy, and the work of orchestration should increasingly focus on boundaries and observability rather than hand-holding the model step by step. The real test, as always, will be the API bill after a few weeks of production use — especially given the tokenizer changes.
Sources
-
Introducing Claude Opus 4.7 — Anthropic https://www.anthropic.com/news/claude-opus-4-7
-
Claude Opus 4.7 System Card — Anthropic https://www.anthropic.com/claude-opus-4-7-system-card
-
Claude API Documentation — Anthropic https://docs.anthropic.com/claude/docs
-
Amazon Bedrock — Claude Models https://aws.amazon.com/bedrock/claude/
-
Vertex AI — Claude on Google Cloud https://cloud.google.com/vertex-ai/generative-ai/docs/partner-models/claude