16 kwietnia 2026 roku Anthropic udostępniło Claude Opus 4.7 — kolejną iterację flagowego modelu, która koncentruje się na zadaniach wymagających długiego kontekstu, autonomicznego wnioskowania i dyscyplinowanego prowadzenia projektów programistycznych. Premiera przypada w momencie, gdy cała branża przesuwa ciężar z pojedynczych zapytań na agentyczne przepływy pracy — sesje, w których model przez wiele godzin planuje, pisze kod, poprawia błędy i raportuje postęp bez nadzoru człowieka. Opus 4.7 to wersja przystosowana właśnie do takich zastosowań: wolniejsza eskalacja błędów, lepsze korzystanie z pamięci między sesjami i wyraźnie silniejsze wyniki na benchmarkach inżynieryjnych.
Co nowego w Claude Opus 4.7
Nowy model utrzymuje ten sam poziom cenowy co poprzednik (5 USD za milion tokenów wejściowych i 25 USD za milion wyjściowych), ale wnosi kilka istotnych ulepszeń w warstwie architektury i sterowania rozumowaniem. To nie jest wyłącznie kosmetyczna aktualizacja — Anthropic deklaruje „znaczące lepsze podążanie za instrukcjami” i sugeruje, że część zespołów będzie musiała ponownie dostroić swoje prompty, aby w pełni wykorzystać potencjał modelu.
Najważniejsze zmiany względem Opus 4.6:
- Poziom wysiłku
xhigh— nowa, pośrednia warstwa wnioskowania pomiędzyhighamax, dająca większą kontrolę nad relacją kosztu do jakości odpowiedzi. - Budżety zadań (task budgets) — parametr pozwalający ograniczyć zużycie tokenów w długich, agentycznych sesjach bez konieczności ręcznego przerywania.
- Ulepszona wizja — obsługa obrazów do 2576 px na dłuższej krawędzi, czyli ok. 3,75 megapiksela — ponad trzykrotnie więcej niż w poprzedniej wersji.
- Komenda
/ultrareview— dedykowany tryb przeglądu kodu dla użytkowników Claude Pro i Max. - Auto mode — autonomiczne podejmowanie decyzji rozszerzone na plan Max.
- Zaktualizowany tokenizer — lepsza obsługa tekstu, ale ten sam prompt może generować 1,0–1,35× więcej tokenów niż dotychczas, co warto uwzględnić w budżetach API.
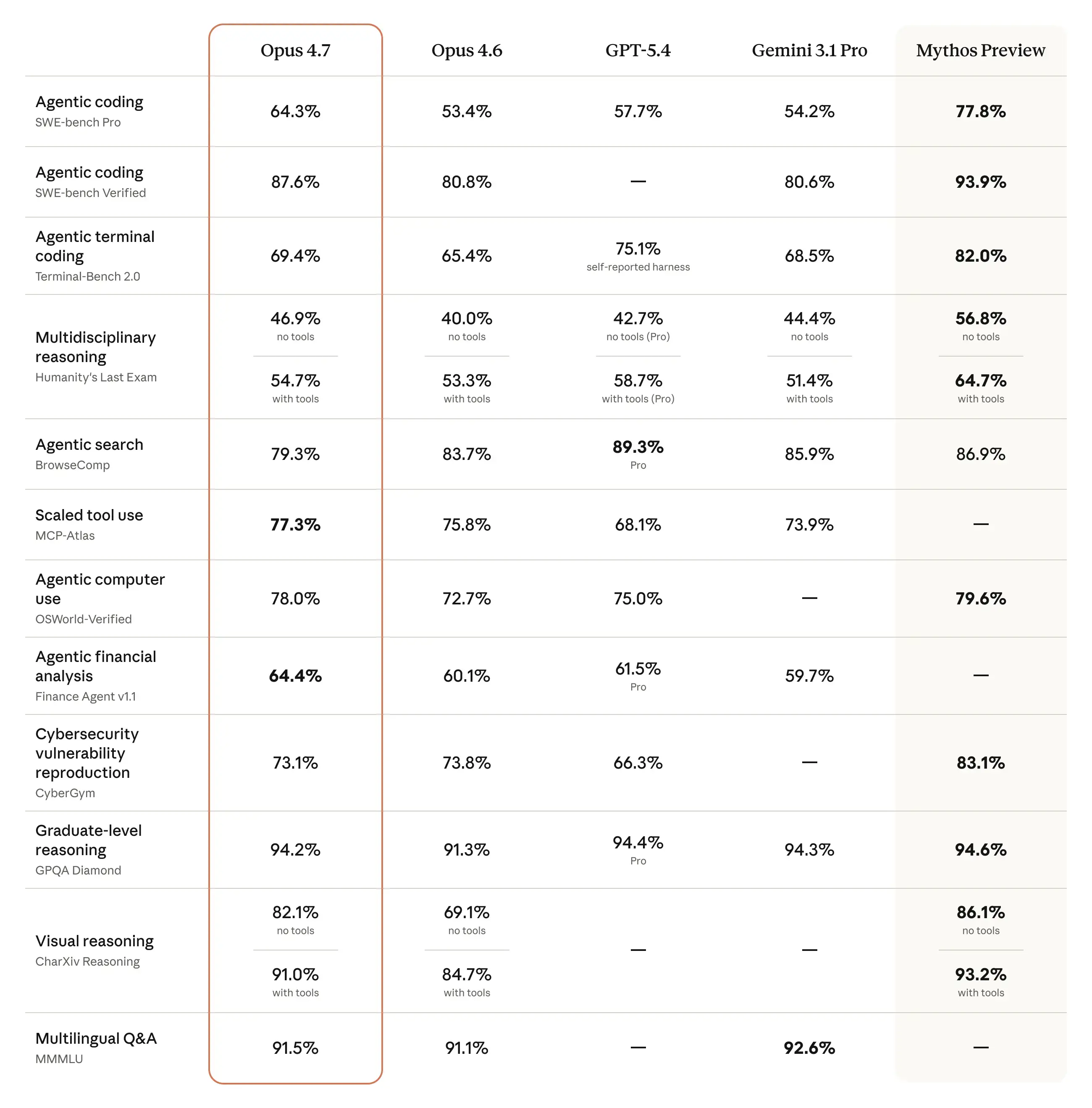
Benchmarki: realne liczby, nie marketing
Anthropic uzupełnia komunikat konkretnymi wynikami pomiarów prowadzonych wspólnie z partnerami produkcyjnymi. To ważna zmiana tonu — zamiast zamkniętych ewaluacji akademickich firma chwali się liczbami z prawdziwych środowisk inżynieryjnych.
| Benchmark / partner | Opus 4.7 | Opus 4.6 |
|---|---|---|
| Replit (93-zadaniowy test kodowania) | +13% | poziom bazowy |
| Rakuten (zadania produkcyjne) | 3× więcej rozwiązań | poziom bazowy |
| CursorBench | 70% sukcesu | 58% sukcesu |
| GDPval-AA (finanse/prawo) | state-of-the-art | niżej |
| XBOW (pentesting) | 98,5% skuteczności wizualnej | — |
Warto zwrócić uwagę na wynik Rakuten — trzykrotny wzrost liczby rozwiązanych zadań produkcyjnych oznacza nie tylko lepszą jakość kodu, ale także większą odporność modelu na „zawieszanie się” w długich przepływach. To bezpośrednio przekłada się na koszty operacyjne: mniej iteracji, mniej zmarnowanych tokenów, mniej poprawek ze strony człowieka.
Agentyczność i pamięć międzysesyjna
Najważniejszy kierunek rozwoju Opusa 4.7 to operowanie w długim horyzoncie czasowym. Model został przystrojony do scenariuszy, w których agent pracuje przez godziny lub dni — pisze kod, uruchamia testy, wraca do zadania po przerwaniu i zachowuje spójność decyzji.
Najważniejsze usprawnienia w tym obszarze:
- Lepsze wykorzystanie pamięci między sesjami — model efektywniej korzysta z wcześniejszych notatek, logów i artefaktów projektu.
- Koordynacja narzędzi — sprawniejsze łączenie wywołań funkcji (tool use) w wielokrokowych planach.
- Stabilność w długim kontekście — mniej „halucynacji zmęczenia” przy pracy z dużymi repozytoriami.
Dla zespołów, które budują własne integracje z modelami klasy Claude — czy to przez API, czy przez Claude Code — oznacza to, że można agresywniej przesuwać logikę do samego modelu, zmniejszając liczbę warstw orkiestracji potrzebnych do utrzymania kontroli.
Zmiany w tokenizatorze: co to oznacza dla rachunków API
Zaktualizowany tokenizer poprawia obsługę tekstu, ale ma praktyczną konsekwencję: te same prompty mogą kosztować więcej. Anthropic podaje współczynnik 1,0–1,35× w zależności od treści, a przy poziomie wysiłku xhigh i max model generuje także więcej tokenów wyjściowych — celowo, w imię większej niezawodności.
Co to oznacza w praktyce dla zespołów produkcyjnych:
- Przegląd budżetów miesięcznych — zwłaszcza tam, gdzie używacie dużych kontekstów lub wielu równoległych agentów.
- Audyt długich promptów — szczególnie wrażliwe są teksty w innych alfabetach i kod z dużą liczbą znaków specjalnych.
- Testy A/B cen jednostkowych — mimo tych samych stawek za milion tokenów, efektywny koszt żądania może być wyższy o 10–35%.
Bezpieczeństwo i podatność na prompt injection
Zewnętrzna ocena bezpieczeństwa modelu jest ostrożnie pozytywna. Opus 4.7 jest oceniany jako „w dużej mierze dobrze zestrojony i godny zaufania”, z wyraźnymi usprawnieniami w obszarze uczciwości oraz odporności na prompt injection — jeden z kluczowych wektorów ataku na systemy agentyczne.
Minusem jest nieco słabsza wydajność modelu w zakresie udzielania porad redukujących szkody (harm-reduction advice), co Anthropic otwarcie komunikuje w dokumentacji. Dla zespołów budujących produkty w obszarach regulowanych — zdrowie, finanse, prawo — oznacza to konieczność utrzymania dodatkowych warstw filtrów i walidacji, podobnie jak w przypadku wcześniejszych modeli tej klasy.
Dostępność i integracje
Claude Opus 4.7 jest dostępny od pierwszego dnia na wszystkich głównych platformach:
- Claude.ai — dla użytkowników Free, Pro, Max oraz Teams/Enterprise.
- API Anthropic — pod identyfikatorem
claude-opus-4-7. - Amazon Bedrock — w regionach obsługujących linię Claude.
- Google Cloud Vertex AI — pełna integracja z pipeline’ami GCP.
- Microsoft Foundry — nowy kanał dystrybucji w ekosystemie Microsoftu.
Dla użytkowników planów Pro i Max dostępna jest także komenda /ultrareview, uruchamiająca dedykowaną sesję przeglądu kodu, w której model poświęca większy budżet obliczeniowy na weryfikację zmian, wychwytywanie regresji i proponowanie uzasadnionych refaktoryzacji.
Podsumowanie
Claude Opus 4.7 to model ewolucyjny, ale w miejscach, które naprawdę mają znaczenie dla zespołów produkcyjnych: długie sesje agentyczne, precyzyjne podążanie za instrukcjami, dyscyplina w wielogodzinnych projektach programistycznych oraz większa kontrola nad relacją kosztu do jakości dzięki nowemu poziomowi xhigh. Trzykrotny wzrost liczby rozwiązanych zadań produkcyjnych u partnerów takich jak Rakuten pokazuje, że poprawa wykracza poza benchmarki i przekłada się na realne oszczędności operacyjne.
Dla firm, które budują procesy oparte o SEO wspierane przez AI lub własne agentyczne narzędzia, Opus 4.7 jest jasnym sygnałem: warstwa modelu zyskuje kolejną porcję autonomii, a praca nad orkiestracją powinna coraz mocniej skupiać się na granicach i obserwowalności, a nie na ręcznym prowadzeniu modelu krok po kroku. Ostateczny test to oczywiście rachunek API po kilku tygodniach użycia — zwłaszcza biorąc pod uwagę zmiany w tokenizatorze.
Źródła
-
Introducing Claude Opus 4.7 — Anthropic https://www.anthropic.com/news/claude-opus-4-7
-
Claude Opus 4.7 System Card — Anthropic https://www.anthropic.com/claude-opus-4-7-system-card
-
Claude API Documentation — Anthropic https://docs.anthropic.com/claude/docs
-
Amazon Bedrock — Claude Models https://aws.amazon.com/bedrock/claude/
-
Vertex AI — Claude on Google Cloud https://cloud.google.com/vertex-ai/generative-ai/docs/partner-models/claude