In 2026, the battle for “Google’s first page” sounds like a story from another era. Today, users rarely click blue links, preferring ready-made answers in chat windows.
The question is no longer: “How do I rank high in search?” but: “How do I make an LLM (Large Language Model) choose my text as its answer source?”
The real challenge is AIO (AI Optimization) – optimizing content so that models (ChatGPT, Perplexity, Claude, or SearchGPT) select it as their primary source and provide an active link. Understanding the mechanisms behind AI citation is key to survival in an ecosystem where your texts – though substantive – can be mathematically ignored by algorithms.

1. The Mirror Paradox: Why AI Loves Reading About Itself
Before diving into technology, it’s worth noting a fascinating trend: LLMs are exceptionally eager to cite content that explains their own mechanisms. This doesn’t stem from machine “narcissism” but from training data quality.
Model creators (OpenAI, Anthropic, Google) feed them massive amounts of technical documentation and scientific papers about neural networks. When you write about how AI works, you use terminology and structure that is the model’s “native language.” Your content then perfectly aligns with vectors the model already knows and considers credible. Using precise language, you become a “trusted partner” for the model, speaking in its native dialect.
“Definition First” Strategy: AI loves clear definitions. Start key sections with simple, encyclopedic sentences explaining a concept. Such construction is an ideal “snippet” for the model, which can transfer it almost unchanged to user responses.
2. Embeddings vs Keywords: The End of the Keyword Dictatorship
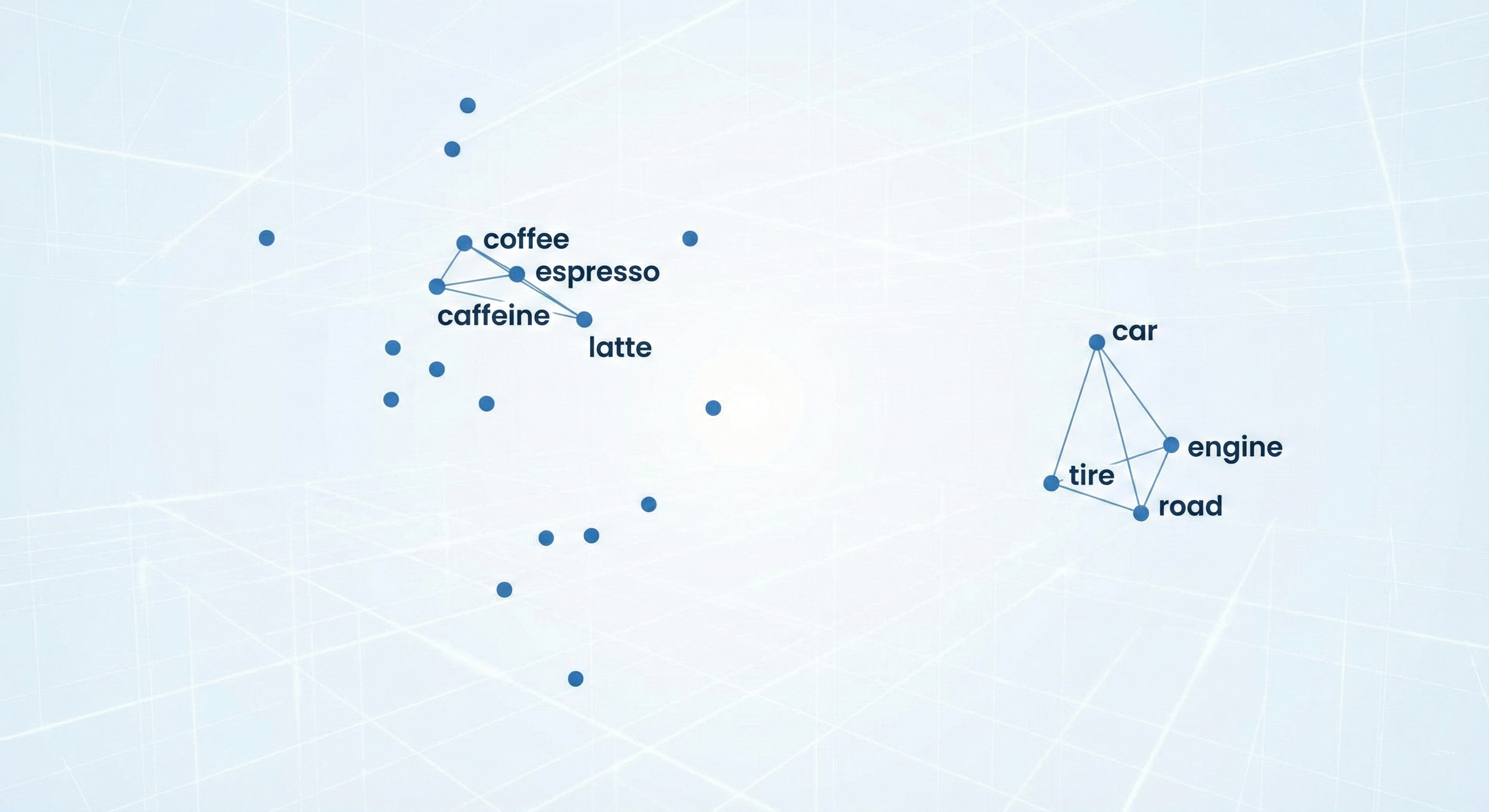
Traditional SEO counted phrase repetitions. In AIO, embedding (vector embedding) counts.
For LLMs, your text isn’t a collection of letters but a point in multidimensional mathematical space. Every fragment of your text is converted into a long string of numbers representing its meaning and context, not just notation.
| Feature | Keywords (Old SEO) | Embeddings (New AIO) |
|---|---|---|
| Mechanism | Character matching (string matching) | Mathematical meaning matching |
| Context | Ignored | Crucial |
| Example | Searches for identical phrase “espresso” | Understands that “espresso” = “small black coffee” |
If a user asks about “ways to boost morning energy,” and you write about “benefits of drinking espresso at dawn,” the model knows these two concepts are close in vector space.
For AI models, “small black coffee” and “espresso” are in the same vector neighborhood. The model doesn’t search for your words – it searches for your intentions.
3. Cosine Similarity: The Math of “Vibe Check”
How does AI know your paragraph fits the question? It calculates cosine similarity between the user query vector A and your text vector B.
The formula used:
If the result is close to 1 (angle close to 0°), it means your content and user intent are nearly identical. The smaller the angle θ (theta) between vectors, the greater the citation chance.
Remember: The clearer and less “fluffy” your text, the sharper its vector and easier the matching. Every unnecessary digression “blurs” your vector, increasing the angle and making your content mathematically irrelevant to the search algorithm.
4. Chunking and RAG: How AI “Consumes” Your Page
AI systems searching for sources (a process called RAG – Retrieval-Augmented Generation) don’t “read” your entire articles from start to finish. The system “quarters” text into chunks (pieces), typically 300–500 tokens.
If your key thesis is in the header but crucial data appears three paragraphs later, AI might “cut” the text so it loses meaning. If your key thesis gets “cut” in half or its proof is in another “chunk,” AI might not connect them.
Golden rule: Every fragment (section) should be self-contained. If the model extracts only this one “chunk,” it must carry complete, understandable information. Each article section must be “modular” and carry full value, even when torn from the rest of the content context.
5. Why FAQs Crush Long Essays
This is the biggest shift in content strategy. Long, flowery essays with elaborate introductions (like “Since the dawn of time, humans wondered what coffee is…”) are extremely inefficient for vector systems.
In AI systems, information density (Information Density) counts. The model has limited “context window” for each chunk. If 500 words contain only one concrete piece of information, the model considers such fragment “noise” and chooses a competitor who provided three facts in 100 words.
Long essays with elaborate introductions carry too little information per “chunk” – they’re inefficient for vector systems.
FAQ (Frequently Asked Questions) wins because:
- Perfect matching: Question in H2 heading often almost perfectly aligns with user query vector.
- Information density: Answer directly under question is condensed, drastically increasing cosine similarity.
- Ready “snippet”: Question-answer pair is an ideal, ready-to-cite module. AI can transfer such structure almost unchanged to chat window, providing link to your page.
6. The Role of Schema.org and Semantic HTML
Models don’t just “read” text - they analyze document structure. Using appropriate HTML tags and structured data is like signposts for LLMs facilitating content understanding:
<article>and<section>: Help algorithm determine “chunk” boundaries and understand content hierarchy.- JSON-LD (Structured Data): Direct knowledge injection into vector database. When describing product, service, or process, structured data is like a “cheat sheet” for AI, easiest to copy from.
- Semantic headings (H1-H6): Proper heading hierarchy helps model identify key topics and subtopics in document.
7. Why “Hallucinations” Are Your Opportunity
LLM models tend to hallucinate when lacking hard data in context window. This is where your role as expert comes in.
If you provide unique data, statistics, or original definitions, the model more eagerly reaches for your source to “anchor” its response in reality. AI strives to minimize error – if your content is the most logical and best-structured proof of a thesis, the model uses it as a “safety net” against fabrication.
Important note: Remember, in 2026 AI no longer searches for answers to “what” questions, but increasingly to “why” and “how.” Therefore, content explaining processes (mechanisms) is prioritized – the model “learns” from them how to better answer in the future.
Practical Comparison: SEO vs. AIO
Table helping understand the paradigm shift:
| Feature | Traditional SEO (Google) | AIO (LLM & SearchGPT) |
|---|---|---|
| Primary Goal | Keywords and Link Building | Meaning (Semantics) and Authority |
| Structure | Long articles, “skyscraper content” | Modularity, FAQ, self-contained blocks |
| Success Metric | SERP Position (Top 10) | Citation Frequency (Citations) |
| Language | Optimized for bots (LSI) | Natural, technical, precise |
| Length | 2000+ words for ranking | Information density > word count |
Summary for Freelancers: How to Write in 2026?
If you want your content to earn in the AI era:
- Forget fluff. Focus on semantic precision and information density.
- Divide text into modular blocks. Each paragraph should stand alone and carry full value, even when torn from context.
- Use technical formatting. Employ tables, lists, definitions, and headings – this helps model extract key information.
- Use precise language. Instead of “things” write “mechanisms,” “processes,” “algorithms” – speak language AI understands.
- Use FAQ structure. This is the shortest path to citation – question in heading perfectly maps to user query.
How Can You Use This Knowledge Today?
Here are 3 practical steps you can implement immediately:
-
“Chunkability” Audit: Review your old texts. If you cut out the middle paragraph, is it still clear what it’s about? If not – add context. Every fragment must be self-contained.
-
Implement data-driven FAQ: Check what users ask (Google Search Console, SEO tools) and create question section. Start answers by repeating question in heading – this perfectly aligns vectors and helps model match.
-
Speak AI language about AI: Even if your blog is about gardening, explaining e.g., “how fertilizer selection algorithm analyzes soil” makes models consider your niche authority higher. Technical nomenclature increases semantic similarity with AI training base.
Bonus: Prompt for Analyzing Your Article
Paste your text into LLM (e.g., Claude or GPT-4) with this command to check how algorithm sees it:
Act as a RAG (Retrieval-Augmented Generation) expert.
Analyze the text below for 'chunkability' (ease of division into modules)
and semantic density.
1. Divide text into logical chunks (about 300-500 tokens).
2. For each chunk, determine 'primary meaning vector'.
3. Rate on scale 1-10 how easily an AI system could cite this fragment
as standalone answer to specific user question.
4. Identify fragments that are 'noise' (add no informational value to
vector database) and reduce citation chances.
Text for analysis: [PASTE TEXT]FAQ: Most Common Questions About AIO (Generative Engine Optimization)
In this section, we've gathered concrete answers to questions most frequently asked by generative search algorithms (and our readers).
Is traditional SEO dead in 2026?
No, SEO hasn't died, but it has evolved. Traditional factors like page speed and domain authority still matter, but AIO (AI Optimization) places greater emphasis on semantics and information structure. While SEO fights for ranking position, AIO fights to become part of the AI-generated answer.
How can I check if AI models are citing my content?
Currently, the best method is direct monitoring of responses in tools like SearchGPT, Perplexity AI, or Google AI Overviews. It's also worth analyzing server logs for visits from bots like OAI-SearchBot (OpenAI) or GoogleOther. More analytics tools (like new versions of Ahrefs or SEMrush) are now offering 'AI Visibility' tracking.
Do I need to know math (like cosine similarity) to write for AI?
You don't need to calculate cosines yourself, but you must understand the principle: fewer unnecessary words = clearer signal for the model. Understanding cosine similarity helps you realize that verbose writing pushes your text away from the user's query in vector space, directly reducing citation chances.
What is the optimal text length for AIO?
In AIO, total article length matters less than block structure (chunking). The ideal information block should be 300 to 500 tokens (about 200-350 words). This length allows full explanation of one topic while fitting within most standard RAG system context windows.
Why do AI models prefer technically structured texts?
LLM models are trained on massive datasets of technical documentation and research papers. Technical structure (clear definitions, bullet points, tables) is least ambiguous for them. This gives the algorithm confidence it's correctly interpreting your content, minimizing hallucination risk and encouraging the model to trust your source.
Sources
- OpenAI - Embeddings Documentation https://platform.openai.com/docs/guides/embeddings
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks https://arxiv.org/abs/2005.11401
- Google Search Central - AI Overviews and web publishers https://developers.google.com/search/blog/2024/04/ai-overviews-and-web-publishers
- Anthropic - How Claude uses context windows https://www.anthropic.com/news/claude-3-family


