W 2026 roku „walka o pierwszą stronę Google” brzmi jak opowieść z innej epoki. Dziś użytkownicy rzadziej klikają w niebieskie linki, a częściej oczekują gotowej odpowiedzi w oknie czatu.
Pytanie nie brzmi już: „Jak być wysoko w wyszukiwarce?”, ale: „Jak sprawić, by LLM (Large Language Model) wybrał mój tekst jako źródło swojej odpowiedzi?”.
Prawdziwe wyzwanie to AIO (AI Optimization) – optymalizacja treści tak, by modele (ChatGPT, Perplexity, Claude czy SearchGPT) wybierały je jako swoje główne źródło i opatrywały aktywnym linkiem. Zrozumienie mechanizmów, które stoją za cytowaniem przez AI, to klucz do przetrwania w ekosystemie, gdzie Twoje teksty – choć merytoryczne – mogą zostać matematycznie pominięte przez algorytmy.

1. Paradoks lustra: Dlaczego AI kocha czytać o sobie?
Zanim przejdziemy do technologii, warto zauważyć fascynujący trend: LLM-y wyjątkowo chętnie cytują treści, które wyjaśniają ich własne mechanizmy. Nie wynika to z „narcyzmu” maszyny, ale z jakości danych treningowych.
Twórcy modeli (OpenAI, Anthropic, Google) karmią je ogromną ilością dokumentacji technicznej i prac naukowych o sieciach neuronowych. Gdy piszesz o tym, jak działa AI, używasz terminologii i struktury, która jest dla modelu „rodzimym językiem”. Twoje treści stają się wtedy idealnie dopasowane do wektorów, które model już zna i uznaje za wiarygodne. Używając precyzyjnego języka, stajesz się dla modelu „wiarygodnym partnerem”, który mówi w jego rodzimym narzeczu.
Strategia “Definition First”: AI uwielbia jasne definicje. Zaczynaj kluczowe sekcje od prostego, encyklopedycznego zdania wyjaśniającego dane pojęcie. Taka konstrukcja to dla modelu idealny „snippet”, który może niemal bez zmian przenieść do odpowiedzi użytkownika.
2. Embeddings vs Keywords: Koniec dyktatury słów kluczowych
W tradycyjnym SEO liczyliśmy powtórzenia fraz. W AIO liczy się embedding (osadzenie wektorowe).
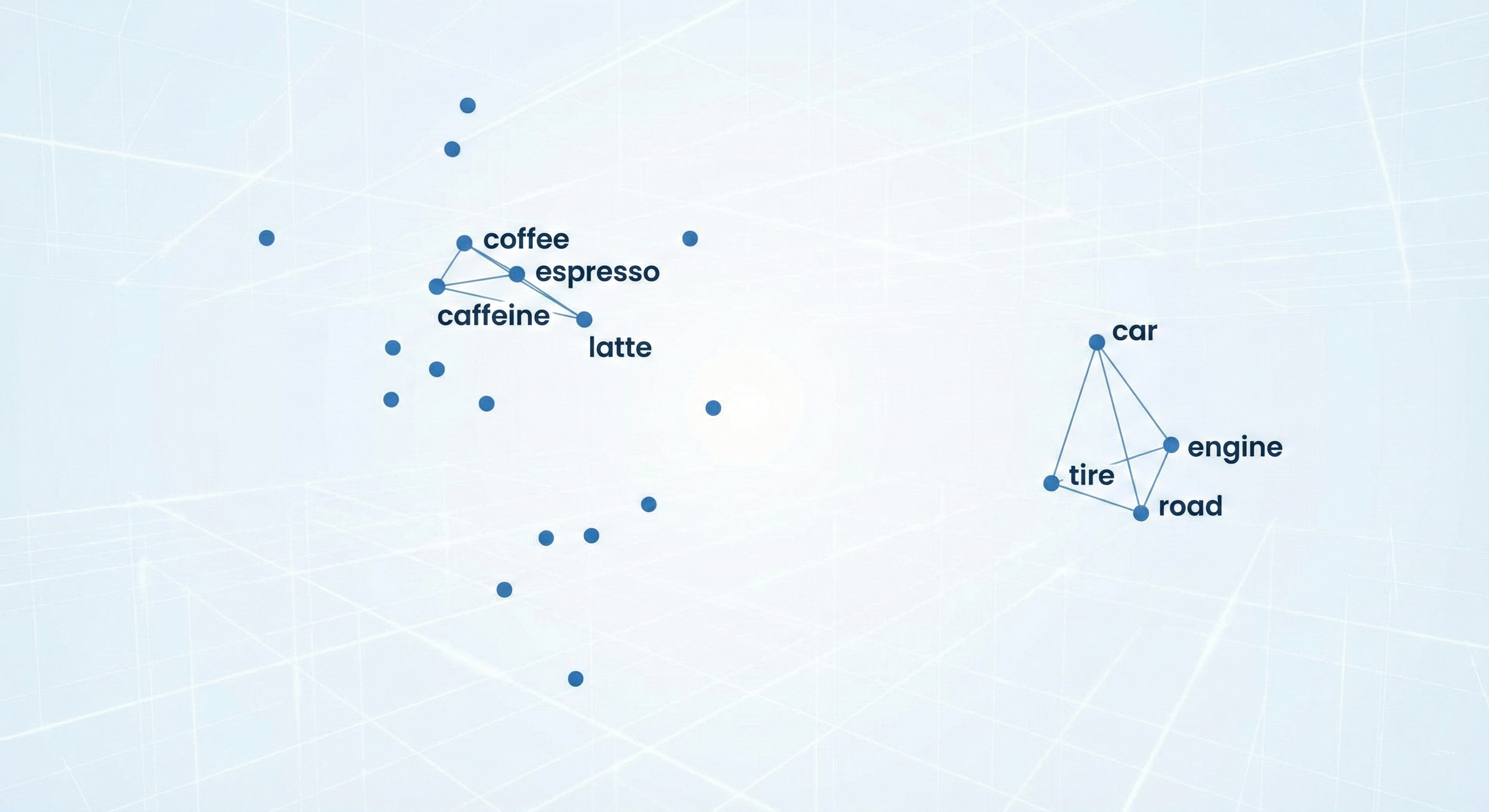
Dla LLM Twój tekst nie jest zbiorem liter, lecz punktem w wielowymiarowej przestrzeni matematycznej. Każdy fragment Twojego tekstu jest zamieniany na długi ciąg liczb reprezentujący jego znaczenie i kontekst, a nie tylko zapis.
| Cecha | Słowa kluczowe (Stare SEO) | Embeddings (Nowe AIO) |
|---|---|---|
| Mechanizm | Dopasowanie znaków (string matching) | Dopasowanie matematycznego sensu |
| Kontekst | Ignorowany | Kluczowy |
| Przykład | Szuka identycznej frazy “espresso” | Rozumie, że “espresso” = “mała czarna” |
Jeśli użytkownik pyta o „sposoby na poranną energię”, a Ty piszesz o „zaletach picia espresso o świcie”, model wie, że te dwa pojęcia leżą blisko siebie w przestrzeni wektorowej.
Dla modelu AI „mała czarna” i „espresso” znajdują się w tej samej okolicy wektorowej. Model nie szuka Twoich słów – szuka Twoich intencji.
3. Cosine Similarity: Matematyka „vibe checku”
Skąd AI wie, że Twój akapit pasuje do pytania? Oblicza podobieństwo cosinusowe (cosine similarity) między wektorem zapytania użytkownika A a wektorem Twojego tekstu B.
Stosuje się do tego wzór:
Jeśli wynik jest bliski 1 (kąt bliski 0°), oznacza to, że Twoja treść i intencja użytkownika to niemal to samo. Im mniejszy kąt θ (theta) między wektorami, tym większa szansa na cytat.
Pamiętaj: Im bardziej klarowny i pozbawiony „lania wody” jest Twój tekst, tym ostrzejszy jest jego wektor i łatwiejsze dopasowanie. Każde zbędne dygresje „rozmywają” Twój wektor, zwiększając kąt i sprawiając, że Twoja treść staje się matematycznie nieistotna dla algorytmu wyszukującego.
4. Chunking i RAG: Jak AI „konsumuje” Twoją stronę
Systemy AI, szukając źródeł (proces zwany RAG – Retrieval-Augmented Generation), nie „czytają” całych Twoich artykułów od początku do końca. System „ćwiartuje” tekst na chunki (kawałki), zazwyczaj po 300–500 tokenów.
Jeśli Twoja kluczowa teza jest w nagłówku, ale kluczowe dane pojawiają się dopiero trzy akapity dalej, AI może „pociąć” tekst tak, że straci on sens. Jeśli Twoja kluczowa teza zostanie „przecięta” w połowie lub dowód na nią znajdzie się w innym „chunku”, AI może ich nie połączyć.
Złota zasada: Każdy fragment (sekcja) powinien być samowystarczalny. Jeśli model wyciągnie tylko ten jeden „chunk”, musi on nieść pełną, zrozumiałą informację. Każda sekcja Twojego artykułu musi być „modularna” i nieść pełną wartość, nawet jeśli zostanie wyrwana z kontekstu reszty wpisu.
5. Dlaczego FAQ miażdży długie eseje?
To największa zmiana w strategii treści. Długie, kwieciste eseje z rozbudowanymi wstępami (typu „Od zarania dziejów człowiek zastanawiał się, czym jest kawa…”) są dla systemów wektorowych skrajnie nieefektywne.
W systemach AI liczy się gęstość informacyjna (Information Density). Model ma ograniczone „okno kontekstowe” dla każdego chunka. Jeśli na 500 słów przypada tylko jedna konkretna informacja, model uzna taki fragment za „szum” i wybierze konkurenta, który w 100 słowach podał trzy fakty.
Długie eseje z rozbudowanymi wstępami niosą zbyt mało informacji w przeliczeniu na „chunk” – są dla systemów wektorowych nieefektywne.
FAQ (Pytania i Odpowiedzi) wygrywa, ponieważ:
- Idealne dopasowanie: Pytanie w nagłówku H2 często niemal idealnie pokrywa się z wektorem zapytania użytkownika.
- Gęstość informacyjna: Odpowiedź bezpośrednio pod pytaniem jest skondensowana, co drastycznie zwiększa cosine similarity.
- Gotowy „snippet”: Para pytanie-odpowiedź to idealny, gotowy do zacytowania moduł. AI może niemal bez zmian przenieść taką strukturę do okna czatu, podając link do Twojej strony.
6. Rola Schema.org i Semantycznego HTML
Modele nie tylko „czytają” tekst - one analizują strukturę dokumentu. Używanie odpowiednich tagów HTML i danych strukturalnych to dla LLM-a drogowskazy ułatwiające zrozumienie treści:
<article>i<section>: Pomagają algorytmowi wyznaczyć granice „chunka” i zrozumieć hierarchię treści.- JSON-LD (Structured Data): To bezpośredni wstrzyk wiedzy do bazy wektorowej. Jeśli opisujesz produkt, usługę lub proces, dane strukturalne są dla AI jak „ściąga”, z której najłatwiej przepisać odpowiedź.
- Semantyczne nagłówki (H1-H6): Prawidłowa hierarchia nagłówków pomaga modelowi zidentyfikować kluczowe tematy i podtematy w dokumencie.
7. Dlaczego „Halucynacje” to Twoja szansa?
Modele LLM mają tendencję do halucynowania, gdy brakuje im twardych danych w oknie kontekstowym. Tutaj pojawia się Twoja rola jako eksperta.
Jeśli dostarczysz unikalne dane, statystyki lub autorskie definicje, model chętniej sięgnie po Twoje źródło, aby „zakotwiczyć” swoją odpowiedź w rzeczywistości. AI dąży do minimalizacji błędu – jeśli Twoja treść jest najbardziej logicznym i najlepiej ustrukturyzowanym dowodem na daną tezę, model użyje jej jako „bezpiecznika” przed zmyślaniem.
Ważna uwaga: Pamiętaj, że w 2026 roku AI nie szuka już odpowiedzi na pytanie „co”, ale coraz częściej na pytanie „dlaczego” i „jak”. Dlatego treści wyjaśniające procesy (mechanizmy) są traktowane priorytetowo – model „uczy się” z nich, jak lepiej odpowiadać w przyszłości.
Praktyczne porównanie: SEO vs. AIO
Tabela, która pomoże zrozumieć zmianę paradygmatu:
| Cecha | Tradycyjne SEO (Google) | AIO (LLM & SearchGPT) |
|---|---|---|
| Główny cel | Słowa kluczowe i Link Building | Znaczenie (Semantyka) i Autorytet |
| Struktura | Długie artykuły, „skyscraper content” | Modularność, FAQ, samowystarczalne bloki |
| Miernik sukcesu | Pozycja w SERP (Top 10) | Częstotliwość cytowań (Citations) |
| Język | Optymalizowany pod roboty (LSI) | Naturalny, techniczny, precyzyjny |
| Długość | 2000+ słów dla pozycji | Gęstość informacyjna > ilość słów |
Podsumowanie dla Freelancera: Jak pisać w 2026?
Jeśli chcesz, aby Twoje treści zarabiały w erze AI:
- Zapomnij o laniu wody. Skup się na precyzji semantycznej i gęstości informacyjnej.
- Dziel tekst na modularne bloki. Każdy akapit powinien bronić się samodzielnie i nieść pełną wartość, nawet gdy zostanie wyrwany z kontekstu.
- Stosuj formatowanie techniczne. Używaj tabelek, list, definicji i nagłówków – to ułatwia modelowi wyodrębnienie kluczowych informacji.
- Używaj precyzyjnego języka. Zamiast „rzeczy” pisz „mechanizmy”, „procesy”, „algorytmy” – mów językiem, który rozumie AI.
- Stosuj strukturę FAQ. To najkrótsza droga do bycia zacytowanym – pytanie w nagłówku idealnie mapuje się na zapytanie użytkownika.
Jak możesz wykorzystać tę wiedzę już dziś?
Oto 3 praktyczne kroki, które możesz wdrożyć natychmiast:
-
Audyt “Chunkability”: Przejrzyj swoje stare teksty. Czy po wycięciu środkowego akapitu, nadal wiadomo, o co w nim chodzi? Jeśli nie – dopisz kontekst. Każdy fragment musi być samowystarczalny.
-
Wdróż FAQ oparte na danych: Sprawdź, o co pytają Twoi użytkownicy (Google Search Console, narzędzia SEO) i stwórz sekcję pytań. Zaczynaj odpowiedź od powtórzenia pytania w nagłówku – to idealnie ustawia wektory i ułatwia modelowi dopasowanie.
-
Mów językiem AI o AI: Nawet jeśli Twój blog jest o ogrodnictwie, wyjaśnienie np. „jak algorytm doboru nawozów analizuje glebę” sprawi, że modele uznają Twój autorytet w tej niszy za wyższy. Techniczna nomenklatura zwiększa semantyczne podobieństwo z bazą treningową AI.
Bonus: Prompt do analizy Twojego artykułu
Wklej swój tekst do LLM (np. Claude lub GPT-4) z tym poleceniem, aby sprawdzić, jak widzi go algorytm:
Działaj jako ekspert od systemów RAG (Retrieval-Augmented Generation).
Przeanalizuj poniższy tekst pod kątem 'chunkability' (łatwości podziału na moduły) oraz gęstości semantycznej.
1. Podziel tekst na logiczne chunki (ok. 300-500 tokenów).
2. Dla każdego chunka określ 'główny wektor znaczenia'.
3. Oceń w skali 1-10, jak łatwo system AI mógłby zacytować dany fragment jako samodzielną odpowiedź na konkretne pytanie użytkownika.
4. Wskaż fragmenty, które są 'szumem' (nie wnoszą wartości informacyjnej do bazy wektorowej) i obniżają szansę na cytowanie.
Tekst do analizy: [WKLEJ TEKST]FAQ: Najczęstsze pytania o AIO (Generative Engine Optimization)
W tej sekcji zebraliśmy konkretne odpowiedzi na pytania, które najczęściej zadają algorytmy wyszukiwania generatywnego (i nasi czytelnicy).
Czy tradycyjne SEO w 2026 roku przestało istnieć?
Nie, SEO nie umarło, ale ewoluowało. Tradycyjne czynniki, takie jak szybkość strony czy autorytet domeny, nadal mają znaczenie, jednak AIO (AI Optimization) kładzie większy nacisk na semantykę i strukturę informacji. Podczas gdy SEO walczy o pozycję w rankingu, AIO walczy o to, by stać się częścią odpowiedzi generowanej przez model AI.
Jak sprawdzić, czy modele AI cytują moje treści?
Obecnie najlepszą metodą jest bezpośrednie monitorowanie odpowiedzi w narzędziach takich jak SearchGPT, Perplexity AI czy Google AI Overviews. Warto również analizować logi serwera pod kątem wizyt botów takich jak OAI-SearchBot (OpenAI) czy GoogleOther. Coraz więcej narzędzi analitycznych (np. nowe wersje Ahrefs czy SEMrush) oferuje już śledzenie 'AI Visibility'.
Czy muszę znać matematykę (np. podobieństwo cosinusowe), aby pisać pod AI?
Nie musisz samodzielnie obliczać cosinusów, ale musisz rozumieć zasadę: im mniej zbędnych słów, tym czystszy sygnał dla modelu. Znajomość mechanizmu cosine similarity pozwala zrozumieć, że pisanie 'na okrętkę' oddala Twój tekst od zapytania użytkownika w przestrzeni wektorowej, co bezpośrednio zmniejsza szansę na cytat.
Jaka jest optymalna długość tekstu dla AIO?
W AIO długość całego artykułu jest mniej ważna niż struktura blokowa (chunking). Idealny blok informacyjny powinien mieć od 300 do 500 tokenów (ok. 200-350 słów). Taka długość pozwala na pełne wyjaśnienie jednego zagadnienia, jednocześnie mieszcząc się w większości standardowych okien kontekstowych systemów RAG.
Dlaczego modele AI preferują teksty o strukturze technicznej?
Modele LLM są trenowane na ogromnych zbiorach dokumentacji technicznej i prac naukowych. Struktura techniczna (jasne definicje, wypunktowania, tabele) jest dla nich najmniej wieloznaczna. Dzięki temu algorytm ma pewność, że poprawnie interpretuje Twoją treść, co minimalizuje ryzyko halucynacji i zachęca model do zaufania Twojemu źródłu.
Źródła
- OpenAI - Embeddings Documentation https://platform.openai.com/docs/guides/embeddings
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks https://arxiv.org/abs/2005.11401
- Google Search Central - AI Overviews and web publishers https://developers.google.com/search/blog/2024/04/ai-overviews-and-web-publishers
- Anthropic - How Claude uses context windows https://www.anthropic.com/news/claude-3-family