
The llms-full.txt standard is an evolution of Jeremy Howard’s September 2024 proposal, designed to deliver a website’s full context in a format native to large language models (LLMs).1 While the base llms.txt file serves as a resource map (table of contents), the llms-full.txt variant is a consolidated Markdown document containing the entire knowledge base.3 Implementing the llms-full.txt standard eliminates the need for repeated HTML page crawling, reducing token consumption by over 90% by stripping visual noise such as navigation, footers, and JavaScript.
Architecture and data hierarchy
The llms-full.txt file structure adapts Markdown hierarchy to serve full-text content.
Key structural components
- H1 heading — project or entity name (the only mandatory element identifying the data source).5
- Summary (blockquote) — a brief project description (1–3 sentences), providing AI assistants with overarching context before analyzing details.6
- Thematic sections (H2) — logical content groups, such as installation instructions or API references.
- Core content (H3 and body text) — in llms-full.txt, links are replaced with full document text, allowing coding assistants to fetch the entire knowledge base in a single request.8
Managing token volume
Implementing llms-full.txt requires monitoring file size relative to a model’s context window. Very large knowledge bases can exceed direct loading capabilities — for example, the Cloudflare documentation in this format can reach millions of tokens, necessitating chunking mechanisms.
Why I removed the llms-full.txt generation option from Uper SEO
The choice of generation tool depends on the site’s scale and architecture. In practice, automatically generating full-text data packages encounters serious logical barriers.
While developing the Uper SEO extension, I decided to remove the automatic llms-full.txt building option. This decision stemmed from the enormous complexity required to create a universal, “clean” document at scale. The biggest challenge is precisely filtering the right content:
- Promotional noise — many pages contain dynamic banners, CTA popups, and fixed info elements that are difficult for HTML-to-Markdown converters to distinguish from the main text.9
- Context pollution — if an AI model receives a file full of navigational “junk,” its response accuracy drops dramatically, defeating the purpose of the llms-full.txt standard.
- Performance — rendering thousands of subpages in a browser via an extension is slow and frequently leads to out-of-memory (OOM) errors on large sites.
Recommendation: dedicated backend and API-first integration
For professional deployments, the most effective method is generating llms-full.txt directly on the backend. This allows data retrieval “at the source” from APIs (e.g., Laravel, REST, or GraphQL), completely bypassing the frontend’s visual layer and eliminating content filtering errors.
Auditing and validation: the Site essentials module in Uper SEO
Proper implementation requires rigorous verification that files are machine-readable. The Uper SEO extension’s Site essentials module automatically scans websites for the presence and correctness of AI assistant control files.
The tool performs deep content inspection, delivering statistics critical to AI system performance. For example, when auditing the Perplexity documentation, the Site essentials module identifies 18,346 thematic sections, a knowledge base volume of approximately 4 million words (~4045k WORDS), and 71,676 links.
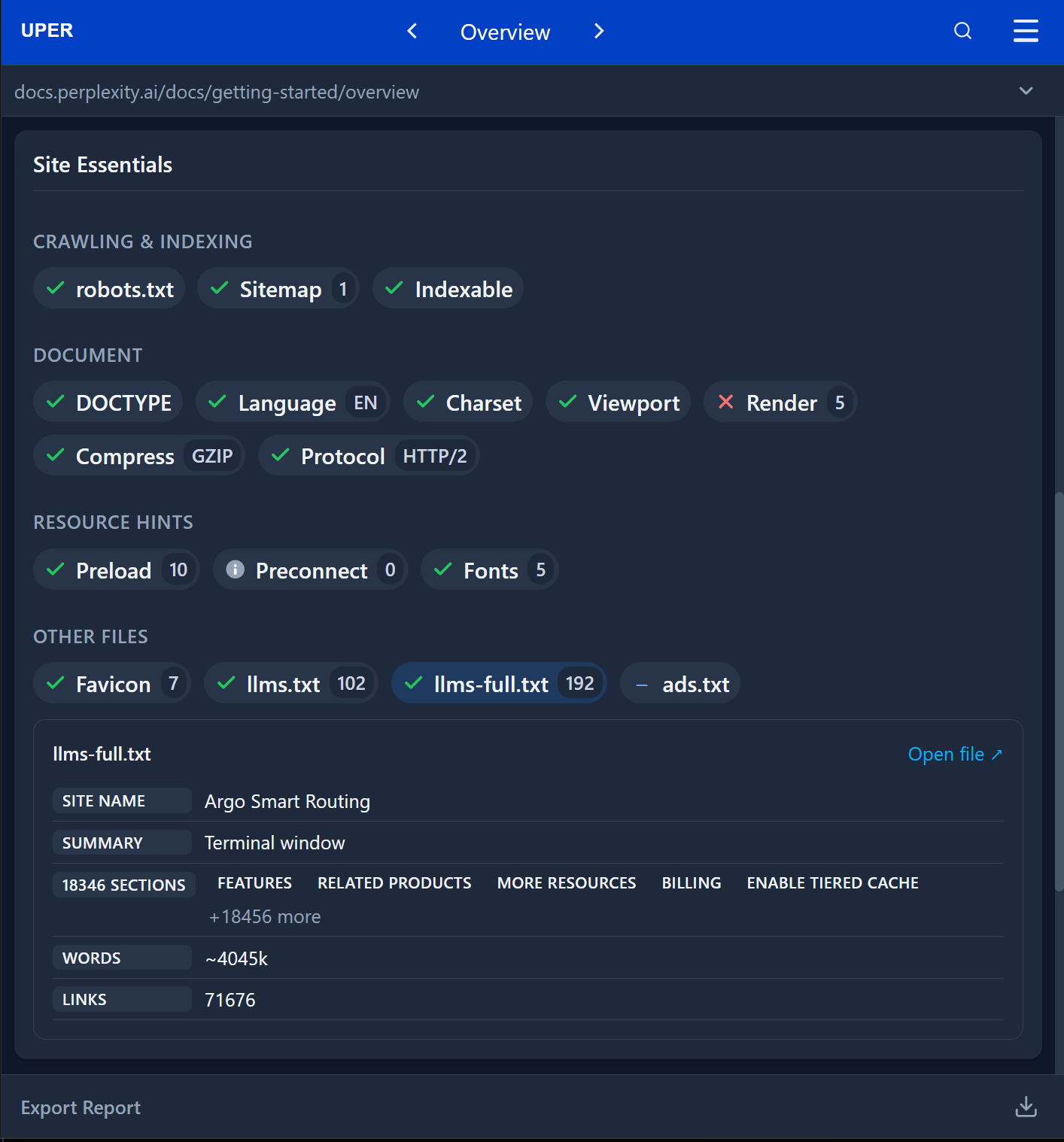
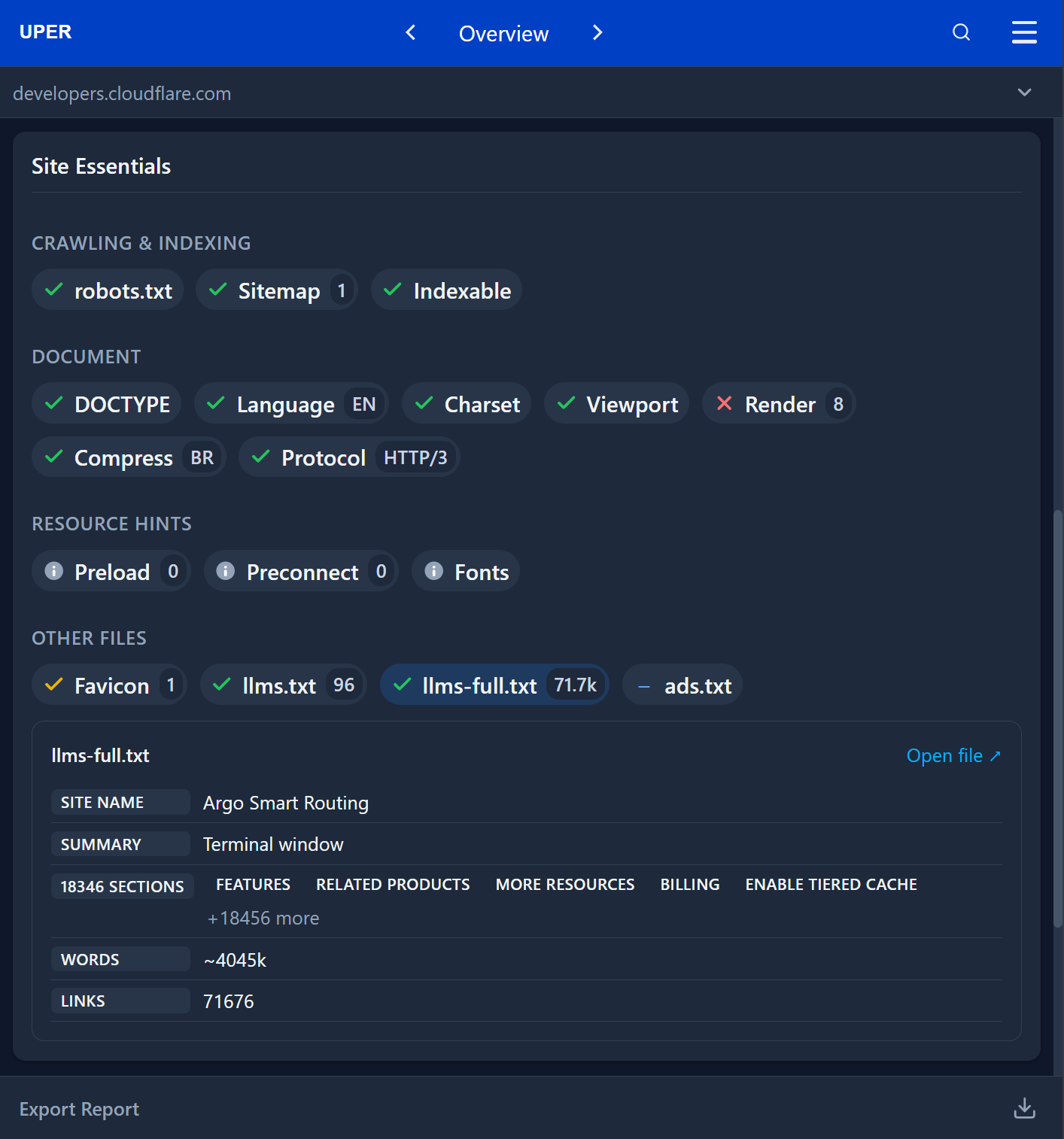
For the Cloudflare documentation, the tool verifies the availability of a full-text file with a volume of 71.7k context units, allowing developers to quickly assess whether the data will fit within a chosen model’s standard context window (e.g., 128k tokens).
Agentic Commerce
The vision of Agentic Commerce — commerce conducted directly by AI agents — is becoming the foundation of a new payment infrastructure. Leaders like Mastercard promote providing llms-full.txt files as “machine-readable company manuals.” This allows AI assistants to automatically generate correct transaction code and understand complex financial policies without the risk of errors from outdated training data.
Real-world llms-full.txt implementations
Analyzing active deployments reveals how truth sources for AI assistants are constructed in practice. It’s worth noting that the standard is still at a very early stage — tech companies, documentation sites, and AI projects dominate, not mainstream media or e-commerce portals.
| Service | Category | File contents |
|---|---|---|
| OpenAI | AI / API | Guides and technical API documentation |
| Perplexity | AI / Search | Project descriptions, Pydantic data models for JSON validation |
| Pinecone | AI / Vector DB | Documentation critical for RAG systems |
| ElevenLabs | AI / Speech | Speech synthesis and voice cloning API |
| MCP | AI / Protocol | Model Context Protocol specification for agents |
| Next.js | Framework | CLI instructions and file structure conventions11 |
| Svelte | Framework | Complete frontend framework documentation |
| Expo | Framework | React Native ecosystem documentation |
| Medusa | E-commerce | Open-source platform with full API description |
| Zapier | SaaS / Automation | Automation processes and documentation organization |
| Mastercard | Fintech | Agent Toolkit for AI agents handling transactions |
| Tidio | SaaS / Chat | Chat platform functionality for agents |
| Polo Blue | OE parts catalog | 2150+ genuine VW Polo parts with OEM numbers and technical specs |
Implementation directory: llmstxt.site
The public directory llmstxt.site aggregates llms.txt and llms-full.txt file locations from across the internet, providing real-time adoption statistics. For each indexed domain, the directory presents file size, section count, and availability status — making it a practical tool for benchmarking your own implementation against competitors and industry leaders.
Current adoption scale and effectiveness analysis
Despite significant interest in the developer community, the standard has not yet reached the ubiquity level of robots.txt files.
- Low market adoption — a study by SE Ranking on a sample of 300,000 domains found that only 10.13% of websites had implemented an llms.txt file.
- No correlation with citations — SE Ranking’s analysis found no statistically significant impact of having the file on citation frequency by major AI models like ChatGPT or Claude.
- Resistance from major players — the largest websites (over 100k visits) adopt the standard less frequently (8.27%) than mid-sized sites (10.54%).
The findings suggest that implementing llms-full.txt is currently a future-proofing investment, preparing a website for the moment when AI assistants begin broadly treating these files as priority knowledge sources.
Optimizing content for reasoning systems
To increase precision, content in llms-full.txt must be written following the principle of semantic independence. Ambiguous pronouns should be avoided in favor of full proper nouns and identifiers. This allows search engines to correctly assign meaning to a fragment, even after it has been isolated from the full document.
The llms-full.txt standard is a key element of Generative Engine Optimization (GEO) strategy. Delivering an organized, noise-free knowledge source directly impacts brand credibility in responses generated by artificial intelligence systems.
Summary
The llms-full.txt file is not just another tech trend — it’s a practical tool for controlling how AI models understand your website. While standard adoption is still at an early stage, companies investing in its implementation gain an advantage in building credibility within the generative search ecosystem. The keys to success are backend-side file generation, regular structural validation, and writing content according to semantic independence principles.
Frequently Asked Questions
What is the difference between llms.txt and llms-full.txt?
llms.txt serves as a table of contents — it contains links with short descriptions that AI models must follow to access detailed information. llms-full.txt is a consolidated Markdown document containing the entire knowledge base in a single file, eliminating the need for multiple page crawls.
Does llms-full.txt affect Google rankings?
The llms-full.txt standard does not directly affect traditional Google rankings. However, it is a key element of Generative Engine Optimization (GEO) strategy — it influences how AI models like ChatGPT, Claude, and Perplexity cite and represent your brand in their responses.
How do I generate an llms-full.txt file?
The most effective method is generating the file directly on the backend by pulling data from APIs (e.g., REST or GraphQL). This bypasses the frontend visual layer and avoids navigational noise. Tools like Mintlify offer automatic generation for technical documentation.
Do major websites use llms-full.txt?
The standard is still at an early adoption stage — it is primarily used by tech companies and AI projects such as OpenAI, Perplexity, Pinecone, Next.js, and Svelte. Mainstream media portals and large e-commerce sites have not yet adopted it at scale.
Sources
-
llms.txt — a proposal to provide information to help LLMs use websites – Answer.AI https://www.answer.ai/posts/2024-09-03-llmstxt.html
-
We Submitted llms.txt to Google Search Console. 3 Days Later, It Was Powering AI Answers – dev5310 https://www.dev5310.com/en/lab/llms-txt-is-powering-ai-answers
-
What Is LLMs.txt? The Guide To AI Search & GEO – Yotpo https://www.yotpo.com/blog/what-is-llms-txt/
-
What is llms.txt? Why it’s important and how to create it for your docs – GitBook Blog https://www.gitbook.com/blog/what-is-llms-txt
-
llms-txt: The /llms.txt file https://llmstxt.org/
-
What Is LLM.txt (aka llms.txt), and Should You Use It? – Singularity Digital Marketing https://singularity.digital/insights/what-is-llms-txt/
-
How to generate llms.txt – Mintlify https://www.mintlify.com/blog/how-to-generate-llmstxt-file-automatically
-
llms.txt – LangGraph GitHub Pages https://langchain-ai.github.io/langgraph/llms-txt-overview/
-
LLMS.txt 2026 Guide AI Agents & GEO Optimization – WebCraft https://webscraft.org/blog/llmstxt-povniy-gayd-dlya-vebrozrobnikiv-2026?lang=en
-
rachfop/docusaurus-plugin-llms – GitHub https://github.com/rachfop/docusaurus-plugin-llms
-
llms-full.txt – Next.js https://nextjs.org/docs/llms-full.txt


