
Standard llms-full.txt stanowi ewolucję propozycji Jeremy’ego Howarda z września 2024 roku, opracowaną w celu dostarczenia pełnego kontekstu witryny w formacie natywnym dla modeli językowych (LLM).1 Podczas gdy bazowy plik llms.txt pełni rolę mapy zasobów (spisu treści), wariant llms-full.txt jest skonsolidowanym dokumentem Markdown zawierającym pełną treść bazy wiedzy.3 Implementacja standardu llms-full.txt pozwala wyeliminować konieczność wielokrotnego skanowania podstron HTML, co redukuje zużycie tokenów o ponad 90% dzięki pominięciu szumu wizualnego, takiego jak nawigacja, stopki czy skrypty JavaScript.
Architektura i hierarchia danych
Struktura pliku llms-full.txt adaptuje hierarchię Markdown do serwowania pełnych treści merytorycznych.
Kluczowe komponenty struktury
- Nagłówek H1 — nazwa projektu lub podmiotu (jedyny obowiązkowy element identyfikujący źródło danych).5
- Streszczenie (blockquote) — krótka charakterystyka projektu (1–3 zdania), dostarczająca asystentom AI nadrzędnego kontekstu przed analizą szczegółów.6
- Sekcje tematyczne (H2) — logiczne grupy treści, takie jak instrukcje instalacji lub referencje API.
- Treść merytoryczna (H3 i tekst) — w pliku llms-full.txt linki są zastępowane pełnym tekstem dokumentów, co umożliwia asystentom programowania pobranie całej bazy wiedzy w jednym zapytaniu.8
Zarządzanie objętością tokenów
Implementacja standardu llms-full.txt wymaga monitorowania rozmiaru pliku w relacji do okna kontekstowego modelu. Bardzo obszerne bazy wiedzy mogą osiągać rozmiary przekraczające możliwości bezpośredniego wczytania — przykładowo dokumentacja Cloudflare w tym formacie może liczyć miliony tokenów, co wymusza stosowanie mechanizmów fragmentacji.
Dlaczego zrezygnowałem z opcji generowania llms-full.txt w Uper SEO?
Wybór narzędzia do generowania plików zależy od skali i architektury serwisu. W praktyce deweloperskiej automatyczne generowanie pełnotekstowych paczek danych napotyka na poważne bariery logiczne.
Podczas prac nad rozwojem wtyczki Uper SEO, zdecydowałem się na usunięcie opcji automatycznego budowania plików llms-full.txt. Decyzja ta wynikała z ogromnej złożoności logiki wymaganej do stworzenia uniwersalnego i “czystego” dokumentu na masową skalę. Największym wyzwaniem jest precyzyjne odfiltrowanie właściwej treści:
- Szum promocyjny — wiele stron zawiera dynamiczne bannery, wyskakujące okna CTA oraz sztywne elementy informacyjne (fixed info), które dla algorytmów konwertujących HTML na Markdown są trudne do odróżnienia od głównego tekstu.9
- Zanieczyszczenie kontekstu — jeśli model AI otrzyma plik pełen “śmieci” nawigacyjnych, precyzja jego odpowiedzi drastycznie spada, co niweluje sens stosowania standardu llms-full.txt.
- Wydajność — proces renderowania tysięcy podstron w przeglądarce przez wtyczkę jest powolny i przy dużych serwisach często prowadzi do błędów pamięci (OOM).
Rekomendacja: dedykowany backend i integracja API-first
Dla profesjonalnych wdrożeń najskuteczniejszą metodą jest generowanie llms-full.txt bezpośrednio na zapleczu (backendzie). Pozwala to na pobieranie danych “u źródła” z API (np. Laravel, REST lub GraphQL), co całkowicie omija warstwę wizualną frontendu i eliminuje błędy filtracji treści.
Audyt i walidacja: moduł Site essentials w Uper SEO
Prawidłowe wdrożenie wymaga rygorystycznej weryfikacji, czy pliki są czytelne dla maszyn. Wtyczka Uper SEO w module Site essentials automatycznie skanuje witrynę pod kątem obecności i poprawności plików sterujących dla asystentów AI.
Narzędzie przeprowadza głęboką inspekcję zawartości, dostarczając statystyk krytycznych dla wydajności systemów sztucznej inteligencji. Przykładowo, podczas audytu dokumentacji Perplexity, moduł Site essentials identyfikuje aż 18 346 sekcji tematycznych, objętość bazy wiedzy na poziomie około 4 milionów słów (~4045k WORDS) oraz 71 676 linków.
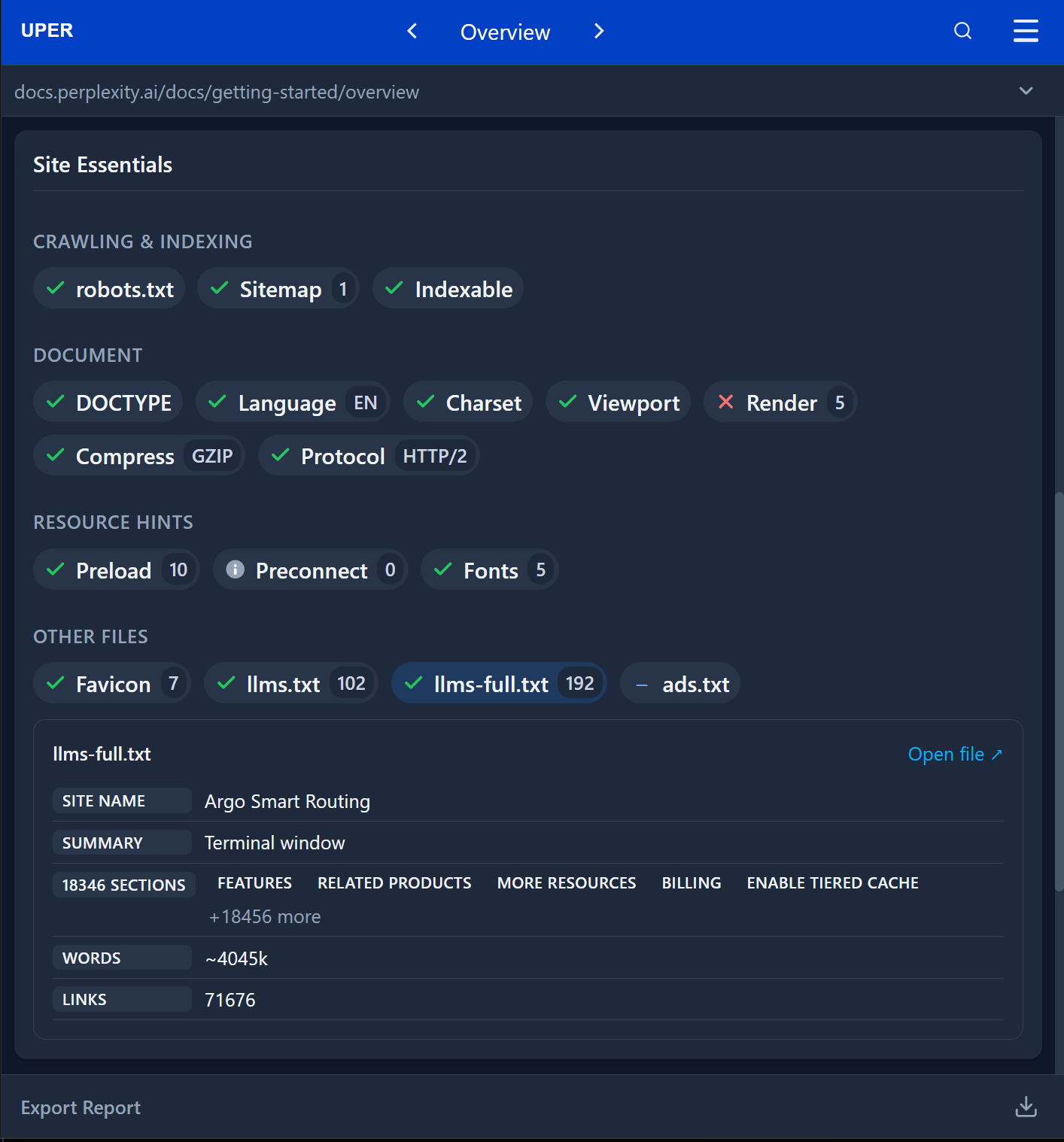
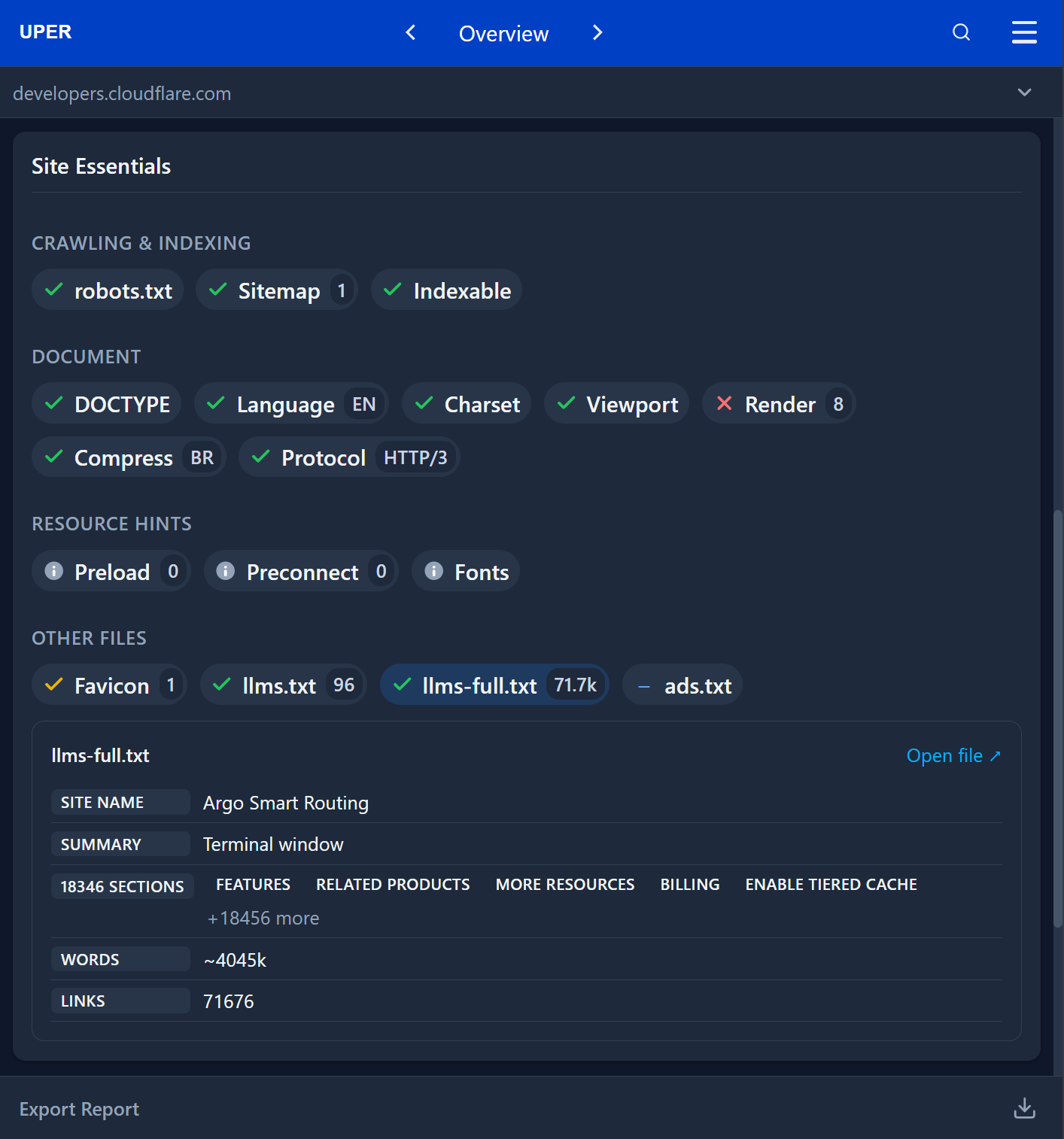
W przypadku dokumentacji Cloudflare, narzędzie weryfikuje dostępność pliku pełnotekstowego o objętości 71,7k jednostek kontekstowych, co pozwala deweloperom na błyskawiczną ocenę, czy dane zmieszczą się w standardowym oknie kontekstowym (np. 128k tokenów) wybranego modelu.
Handel agentyczny (Agentic Commerce)
Wizja Agentic Commerce, czyli handlu prowadzonego bezpośrednio przez agenty AI, staje się fundamentem nowej infrastruktury płatniczej. Liderzy tacy jak Mastercard promują udostępnianie plików llms-full.txt jako “instrukcji obsługi firmy” dla maszyn. Pozwala to asystentom AI na automatyczne generowanie poprawnego kodu transakcyjnego i zrozumienie skomplikowanych polityk finansowych bez ryzyka błędu wynikającego z nieaktualnych danych treningowych.
Rzeczywiste przykłady implementacji llms-full.txt
Analiza aktywnych wdrożeń pozwala zrozumieć, jak w praktyce konstruowane są źródła prawdy dla asystentów AI. Warto zaznaczyć, że standard jest wciąż na bardzo wczesnym etapie — dominują firmy technologiczne, dokumentacje i projekty AI, a nie klasyczne duże portale mediowe czy e-commerce.
| Serwis | Kategoria | Zawartość pliku |
|---|---|---|
| OpenAI | AI / API | Przewodniki i dokumentacja techniczna interfejsów API |
| Perplexity | AI / Wyszukiwarka | Opisy projektów, modele danych Pydantic do walidacji JSON |
| Pinecone | AI / Baza wektorowa | Dokumentacja kluczowa dla systemów RAG |
| ElevenLabs | AI / Speech | API do syntezy mowy i klonowania głosu |
| MCP | AI / Protokół | Specyfikacja Model Context Protocol dla agentów |
| Next.js | Framework | Instrukcje CLI i konwencje struktury plików11 |
| Svelte | Framework | Kompletna dokumentacja frameworka frontendowego |
| Expo | Framework | Dokumentacja ekosystemu React Native |
| Medusa | E-commerce | Open-source’owa platforma z pełnym opisem API |
| Zapier | SaaS / Automatyzacja | Procesy automatyzacji i organizacja dokumentacji |
| Mastercard | Fintech | Agent Toolkit dla agentów AI obsługujących transakcje |
| Tidio | SaaS / Czat | Funkcjonalności platformy czatowej dla agentów |
| Polo Blue | Katalog części OE | 2150+ oryginalnych części VW Polo z numerami OEM i specyfikacją techniczną |
Katalog wdrożeń: llmstxt.site
Publiczny katalog llmstxt.site agreguje lokalizacje plików llms.txt i llms-full.txt z całego internetu, dostarczając statystyki adopcji w czasie rzeczywistym. Dla każdej zindeksowanej domeny katalog prezentuje rozmiar pliku, liczbę sekcji oraz status dostępności — co czyni go praktycznym narzędziem do benchmarkingu własnej implementacji na tle konkurencji i liderów branży.
Aktualna skala adopcji i analiza skuteczności
Mimo dużego zainteresowania w środowisku deweloperskim, standard nie osiągnął jeszcze poziomu powszechności właściwego dla plików robots.txt.
- Niska adopcja rynkowa — badanie przeprowadzone przez SE Ranking na próbie 300 000 domen wykazało, że tylko 10,13% witryn zaimplementowało plik llms.txt.
- Brak korelacji z cytowaniami — analiza SE Ranking nie wykazała statystycznie istotnego wpływu posiadania pliku na częstotliwość cytowania witryny przez główne modele AI, takie jak ChatGPT czy Claude.
- Opór największych graczy — największe witryny (powyżej 100 tys. wizyt) wdrażają standard rzadziej (8,27%) niż serwisy średniej wielkości (10,54%).
Wnioski sugerują, że implementacja llms-full.txt jest obecnie działaniem o charakterze inwestycyjnym (Future-Proofing), przygotowującym witrynę na moment, w którym asystenci AI zaczną powszechnie traktować te pliki jako priorytetowe źródła wiedzy.
Optymalizacja treści pod systemy wnioskowania
Aby zwiększyć precyzję, treść w llms-full.txt musi być redagowana zgodnie z zasadą niezależności semantycznej. Należy unikać niejednoznacznych zaimków na rzecz pełnych nazw własnych i identyfikatorów. Pozwala to silnikom wyszukiwania na poprawne przypisanie znaczenia do fragmentu, nawet po jego wyizolowaniu z całego dokumentu.
Standard llms-full.txt jest kluczowym elementem strategii Generative Engine Optimization (GEO). Dostarczenie uporządkowanego i pozbawionego szumu źródła wiedzy bezpośrednio wpływa na wiarygodność marki w odpowiedziach generowanych przez systemy sztucznej inteligencji.
Podsumowanie
Plik llms-full.txt to nie kolejny trend technologiczny, lecz praktyczne narzędzie do kontrolowania sposobu, w jaki modele AI rozumieją Twoją witrynę. Choć adopcja standardu jest wciąż na wczesnym etapie, firmy inwestujące w jego wdrożenie zyskują przewagę w budowaniu wiarygodności w ekosystemie generatywnych wyszukiwarek. Kluczem do sukcesu jest generowanie pliku po stronie backendu, regularna walidacja jego struktury oraz redagowanie treści zgodnie z zasadami niezależności semantycznej.
Często zadawane pytania
Czym różni się llms.txt od llms-full.txt?
Plik llms.txt pełni rolę spisu treści — zawiera linki z krótkimi opisami, po których model AI musi podążać, aby uzyskać szczegółowe informacje. Natomiast llms-full.txt to skonsolidowany dokument Markdown zawierający pełną treść bazy wiedzy w jednym pliku, co eliminuje potrzebę wielokrotnego crawlowania podstron.
Czy llms-full.txt wpływa na pozycjonowanie w Google?
Standard llms-full.txt nie wpływa bezpośrednio na tradycyjne pozycjonowanie w Google. Jest natomiast kluczowym elementem strategii Generative Engine Optimization (GEO) — wpływa na to, jak modele AI takie jak ChatGPT, Claude czy Perplexity cytują i reprezentują Twoją markę w swoich odpowiedziach.
Jak wygenerować plik llms-full.txt?
Najskuteczniejszą metodą jest generowanie pliku bezpośrednio na backendzie, pobierając dane z API (np. REST lub GraphQL). Pozwala to ominąć warstwę wizualną frontendu i uniknąć szumu nawigacyjnego. Narzędzia takie jak Mintlify oferują automatyczne generowanie dla dokumentacji technicznej.
Czy duże serwisy stosują llms-full.txt?
Standard jest wciąż na wczesnym etapie adopcji — stosują go głównie firmy technologiczne i projekty AI, takie jak OpenAI, Perplexity, Pinecone, Next.js czy Svelte. Klasyczne duże portale mediowe i e-commerce jeszcze go nie wdrożyły na szeroką skalę.
Źródła
-
llms.txt — a proposal to provide information to help LLMs use websites – Answer.AI https://www.answer.ai/posts/2024-09-03-llmstxt.html
-
We Submitted llms.txt to Google Search Console. 3 Days Later, It Was Powering AI Answers – dev5310 https://www.dev5310.com/en/lab/llms-txt-is-powering-ai-answers
-
What Is LLMs.txt? The Guide To AI Search & GEO – Yotpo https://www.yotpo.com/blog/what-is-llms-txt/
-
What is llms.txt? Why it’s important and how to create it for your docs – GitBook Blog https://www.gitbook.com/blog/what-is-llms-txt
-
llms-txt: The /llms.txt file https://llmstxt.org/
-
What Is LLM.txt (aka llms.txt), and Should You Use It? – Singularity Digital Marketing https://singularity.digital/insights/what-is-llms-txt/
-
How to generate llms.txt – Mintlify https://www.mintlify.com/blog/how-to-generate-llmstxt-file-automatically
-
llms.txt – LangGraph GitHub Pages https://langchain-ai.github.io/langgraph/llms-txt-overview/
-
LLMS.txt 2026 Guide AI Agents & GEO Optimization – WebCraft https://webscraft.org/blog/llmstxt-povniy-gayd-dlya-vebrozrobnikiv-2026?lang=en
-
rachfop/docusaurus-plugin-llms – GitHub https://github.com/rachfop/docusaurus-plugin-llms
-
llms-full.txt – Next.js https://nextjs.org/docs/llms-full.txt


